Language
Our Services




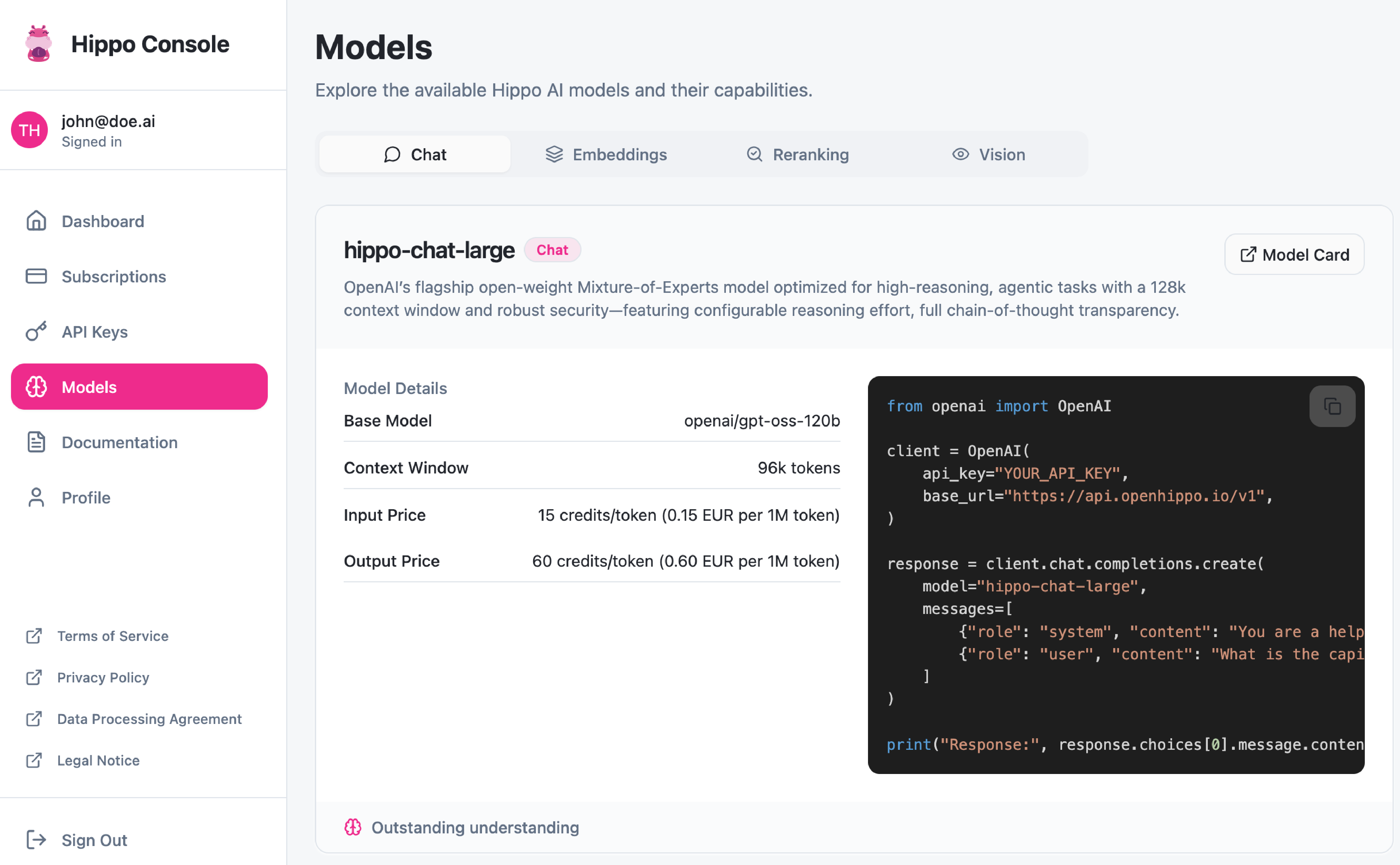
On-Premises AI Server
Hippo Server puts Hippo Chat, Hippo API, and whatever else you need on a server in your building. Your data never leaves your network — not to a cloud provider, not to a model vendor, not to anyone. Full control. Full compliance. Full peace of mind.

What's the problem?
Do you know where your data goes when you use AI?
Every prompt you send to a cloud AI crosses a network boundary. Your confidential documents, customer records, internal strategy — it all passes through infrastructure you don't own, operated by companies in jurisdictions you can't control.
For regulated industries, that's a liability. For everyone else, it's a question your legal team will eventually ask. And once data has left your network, there's no taking it back.
Hippo Server keeps everything in-house. The model runs in your building, on your hardware, under your policies. You always know exactly where your data is — because it never went anywhere.
How does it work?
Four steps to your own AI server.
From discovery workshop to a running system in four weeks.
Workshop: understanding your needs
We sit down with your team and map out what you need — which products, which models, which integrations. You walk away with a clear spec and a realistic picture of what the hardware needs to handle.
We configure the right setup for you
Based on your workload, we select which Open Hippo products go on the server — Hippo Chat, Hippo API, or anything else you need. We pick the models and make sure everything fits your use case and hardware budget.
We set everything up
Hardware procurement, OS setup, software deployment, networking. We handle the full stack. Four weeks from signed contract to a running system on your premises.
Integration and onboarding workshops
We connect the server to your existing systems and run hands-on workshops so your team can operate, manage, and extend it independently from day one.
What's under the hood?
Production-grade open-source stack.
No vendor lock-in, no black boxes — every layer is auditable and battle-tested at scale.

Ubuntu
Rock-solid LTS base. Battle-tested for server workloads, with long-term security support and full hardware compatibility.
NVIDIA
Blackwell GPUs running CUDA for maximum inference throughput on the latest open-weight models.
vLLM
High-throughput LLM serving with PagedAttention. Handles concurrent requests efficiently across all model sizes.
LiteLLM
Unified OpenAI-compatible proxy across all models and providers. One endpoint, full observability, spend controls.
What do you get?
Measurable results, not promises.
Concrete outcomes your team can track from week one.
Does it work in practice?

"The sandbox let us prototype with real patient data from day one — something we could never do with a cloud service."
Got questions?
Common questions about Hippo Server.
Straight answers on hardware, setup, and what to expect.
How long does the setup take?
Four weeks from signed contract to production. Week one is the discovery workshop and hardware spec. Week two covers procurement and infrastructure setup. Week three is software deployment and configuration. Week four is integration, testing, and handover with onboarding workshops for your team.
What does it cost?
Hardware starts at €40,000 for a dual Blackwell RTX 6000 Max configuration — the right choice for production workloads running multiple models and products in parallel. If you want to start smaller, we offer a DGX Spark entry package including the setup workshop for €8,000. That's a practical way to validate the approach before committing to full production hardware.
What's the difference between the DGX Spark package and the full setup?
The DGX Spark package is designed for piloting — you get real hardware, real software, and a real workshop, but at a fraction of the cost. It's ideal for teams that want to prove the business case internally before going to production. The dual Blackwell RTX 6000 Max setup is for production workloads where throughput, reliability, and uptime matter.
Which software runs on the server?
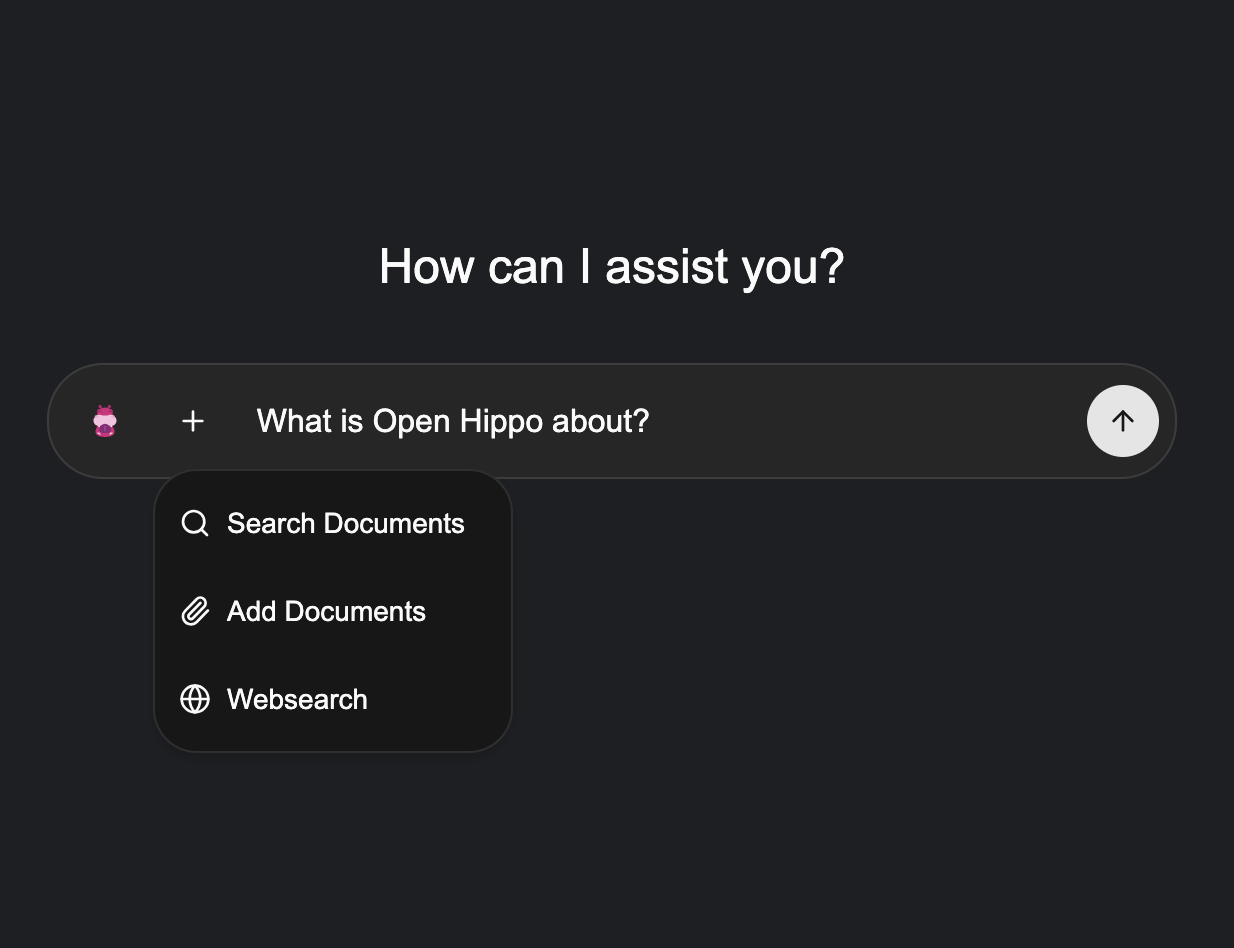
Whatever you need. Hippo Chat gives your team a private, self-hosted AI assistant. Hippo API gives your developers an OpenAI-compatible endpoint they can call from any application. We can add other models and tools on top depending on your use case — the workshop in step one is where we figure that out together.
Does it work without internet access?
Yes. Hippo Server is fully self-contained — no cloud calls, no telemetry, no external dependencies at runtime. This makes it suitable for air-gapped environments, regulated industries, and any setting where outbound data transfer is not acceptable.
Can we add more software later?
Yes. The server is built to be extended. If your needs grow — new models, new tools, new integrations — we can add them without replacing the hardware or starting over. We stay available for support and expansions after the initial handover.
Works with your stack?
Compatible with everything.
Our OpenAI-compatible endpoints plug into any tool that speaks the standard API. We configure and install whichever of these you need — no custom integration work on your side.
n8n
Visual workflow builder with 400+ integrations. Automate any business process with AI nodes that call your models directly — no code required.
Workflow AutomationOpenClaw
Autonomous AI agent running locally on your machine. Operates through WhatsApp, Telegram, or Slack — reads files, controls browsers, manages email.
AI AgentOpen WebUI
Full-featured, self-hosted chat UI for any OpenAI-compatible model. Your private ChatGPT deployment, fully under your control.
Chat InterfaceLibreChat
Multi-provider chat UI in one place. Switch between models mid-conversation, keep full history, and run it entirely on your own infrastructure.
Chat InterfaceMake
The most-used visual automation platform globally. Connect 2,000+ apps in multi-step workflows with AI modules that call your models at any step.
Workflow AutomationZapier
Automate work across 7,000+ apps with trigger-action flows. AI steps can generate text, classify data, or route decisions through your own models.
Workflow AutomationFlowise
Drag-and-drop AI workflow builder. Chain model calls, retrieval steps, and tools visually — without writing agent code.
LLM WorkflowsCline
Autonomous AI coding agent for VS Code. Plans and executes multi-file changes, runs commands, and browses docs — routed through your own endpoint.
IDE ExtensionContinue
Open-source AI code assistant for VS Code and JetBrains. Point completions and chat at any OpenAI-compatible backend — fully self-hosted.
IDE ExtensionClaude Code
Anthropic's official agentic CLI for software engineering. Configurable to route through any OpenAI-compatible endpoint for fully on-premise AI-assisted development.
AI Coding Agent1000+
Any app that speaks the OpenAI API works out of the box — no custom integration needed.

Let's look at your setup.
30 minutes, no pitch deck. We'll map your current AI usage and show you exactly what a Hippo Server would look like for your team.